
前言
这一篇写一点关于算法的内容。算法虽然复杂,难度相对较高,但想要迈向更高的台阶,我们又得掌握其中的奥秘。说到算法,我们就不能不提搜索,说到搜索,我们就不能不提深度和广度搜索,而提及深度和广度,我们就得说到说到队列和栈。
数据结构:栈和队列
栈(Stack)
熟悉编程的人都应该听说过这个网站(Stackoverflow),这里面的Stack就是我今天介绍的栈,而Stackoverflow代表着栈溢出的意思。栈的特点有什么呢?什么又是栈溢出呢?
先来说说栈:
- 一种数据结构的表现用来储存数据
- 栈可以用list列表来实现
- Last-in,First-out
- 只能从顶部进栈和出栈

栈溢出(Stackoverflow)
在这里简单解释一下这个问题,不会深入展开。我们都知道任何关于数据的操作都会调用计算机的内存,而当我们的程序超出内存的承载范围就会发生溢出的情况。在Python中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出
From Baidu
栈实现
根据下面的代码可以验证上述栈的特点
1 | class Stack(object): |
队列(Queue)
队列是另一种数据结构的表现形式,我们应该怎么理解队列呢?队列跟栈又有什么区别呢?
- 数据结构的一种表现形式
- 队列可以用列表和链表来实现
- First-in, First out(先进先出)-其实就按字面意思理解即可,咱们日常怎么排队,队列在代码中就怎么工作,原理是一样的。
链表实现
链表是由一系列节点(Node)组成的队列,每个节点包含两个要素(data,next).通过节点之间的串联,从而形成一个链表。

我们可以大概总结一下,要想完成链表的实现,首先我们的程序需要先构造头节点:Head,然后构造数据基础结构:Node,最后在构造队列。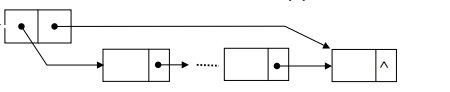
1 | class Node(object): |
指定位置插入数据
1 | def insert(self,pos,data): |
搜索算法:深度和广度
第一次看到搜索算法,还是前几月上网课听到的,当时听起来没那么复杂阿,但看了个网课给的作业直接给我干懵了,这不还是验证了写代码这东西,光看懂还真不大行。:(
给来个网课的链接:https://cs50.harvard.edu/ai/
如何理解搜索算法呢?
- 我们可以把搜索想像成走迷宫,我们有一个初始点和目标点,为了完成从初始点到目标点的过程,我们需要遍临两点中间其他的点,而在遍临点位中,根据要求不同,所走的路径也会有所区别。从初始点到目标点的路径,我个人认为就是我们所谓的搜索算法。而深度和广度,我们直接就可以从字面上来理解了。
例如:如何从A点走到D点
1 | maze={ |
深度搜索(Deep-first-search)
特点:
- 栈实现
- 走到无路径可走
- 有一定的概率是计算最快的解法,但不是最优路径
- 最坏的结果是遍临所有节点
每次从栈的尾部弹出一个元素,搜算与其相连的下一个元素,直到下一元素没有与其相连的节点,如果是目标值则返回,反之退回上一元素,寻找有无与上一元素相连的其他节点。
1 | def DFS(graph,s): |
广度搜索(Breadth-first-search)
特点:
- 队列实现
- 一定找到最优路径(This algorithm is guaranteed to find the optimal solution)
- 时间长
从包含初始状态的节点开始,依次向下探索,层序遍历
1 | def BFS(graph,s): |
Updated on 8/26/20